LINQ has revolutionised the way we do data access. Being able to fluently describe queries in C# means that you never have to write a single line of SQL again. Of course LINQ isn't the only game in town. NHibernate has a rich API for describing queries as do most mature ORM tools. But to be a player in the .NET ORM game you simply have to provide a LINQ IQueryable API. It's been really nice to see the NHibernate-to-LINQ project take off and apparently LLBLGen Pro has an excellent LINQ implementation too.
Now that we can write our queries in C# it should mean that we can have completely DRY business logic. No more duplicate rules, one set in SQL, the other in the domain classes. But there's a problem: LINQ doesn't understand IL. If you write a query that includes a property or method, LINQ-to-SQL can't turn the logic encapsulated by it into a SQL statement.
To illustrate the problem take this simple schema for an order:
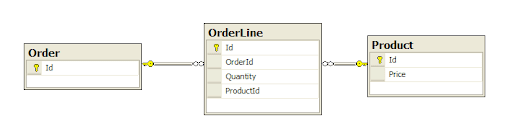
Let's use the LINQ-to-SQL designer to create some classes:
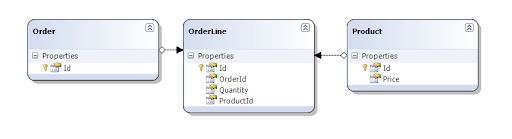
Now lets create a 'Total' property for the order that calculates the total by summing the order lines' quantities times their product's price.
public decimal Total
{
get
{
return OrderLines.Sum(line => line.Quantity * line.Product.Price);
}
}
Here's a test to demonstrate that it works
[Test]
public void Total_ShouldCalculateCorrectTotal()
{
const decimal expectedTotal = 23.21m + 14.30m * 2 + 7.20m * 3;
var widget = new Product { Price = 23.21m };
var gadget = new Product { Price = 14.30m };
var wotsit = new Product { Price = 7.20m };
var order = new Order
{
OrderLines =
{
new OrderLine { Quantity = 1, Product = widget},
new OrderLine { Quantity = 2, Product = gadget},
new OrderLine { Quantity = 3, Product = wotsit}
}
};
Assert.That(order.Total, Is.EqualTo(expectedTotal));
}
Now, what happens when we use the Total property in a LINQ query like this:
[Test]
public void Total_ShouldCalculateCorrectTotalOfItemsInDb()
{
var total = dataContext.Orders.Select(order => order.Total).First();
Assert.That(total, Is.EqualTo(expectedTotal));
}
The test passes, but when we look at the SQL that was generated by LINQ-to-SQL we get this:
SELECT TOP (1) [t0].[Id]
FROM [dbo].[Order] AS [t0]
SELECT [t0].[Id], [t0].[OrderId], [t0].[Quantity], [t0].[ProductId]
FROM [dbo].[OrderLine] AS [t0]
WHERE [t0].[OrderId] = @p0
-- @p0: Input Int (Size = 0; Prec = 0; Scale = 0) [1]
SELECT [t0].[Id], [t0].[Price]
FROM [dbo].[Product] AS [t0]
WHERE [t0].[Id] = @p0
-- @p0: Input Int (Size = 0; Prec = 0; Scale = 0) [1]
SELECT [t0].[Id], [t0].[Price]
FROM [dbo].[Product] AS [t0]
WHERE [t0].[Id] = @p0
-- @p0: Input Int (Size = 0; Prec = 0; Scale = 0) [2]
SELECT [t0].[Id], [t0].[Price]
FROM [dbo].[Product] AS [t0]
WHERE [t0].[Id] = @p0
-- @p0: Input Int (Size = 0; Prec = 0; Scale = 0) [3]
LINQ-to-SQL doesn't know anything about the Total property, so it does as much as it can. It loads the Order. When the Total property executes, OrderLines is evaluated which causes the order lines to be loaded with a single select statement. Next each Product property of each OrderLine is evaluated in turn causing each Product to be selected individually. So we've had five SQL statements executed and the entire Order object graph loaded into memory just to find out the order total. Yes of course we could add data load options to eagerly load the entire object graph with one query, but we would still end up with the entire object graph in memory. If all we wanted was the order total this is very inefficient.
Now, if we construct a query where we explicitly ask for the sum of order line quantities times product prices, like this:
[Test]
public void CalculateTotalWithQuery()
{
var total = dataContext.OrderLines
.Where(line => line.Order.Id == 1)
.Sum(line => line.Quantity * line.Product.Price);
Assert.That(total, Is.EqualTo(expectedTotal));
}
We get this SQL
SELECT SUM([t3].[value]) AS [value]
FROM (
SELECT (CONVERT(Decimal(29,4),[t0].[Quantity])) * [t2].[Price] AS [value], [t1].[Id]
FROM [dbo].[OrderLine] AS [t0]
INNER JOIN [dbo].[Order] AS [t1] ON [t1].[Id] = [t0].[OrderId]
INNER JOIN [dbo].[Product] AS [t2] ON [t2].[Id] = [t0].[ProductId]
) AS [t3]
WHERE [t3].[Id] = @p0
-- @p0: Input Int (Size = 0; Prec = 0; Scale = 0) [1]
One SQL statement has been created that returns a scalar value for the total. Much better. But now we've got duplicate business logic. We have definition of the order total calculation in the Total property of Order and another in the our query.
So what's the solution?
What we need is a way of creating our business logic in a single place that we can use in both our domain properties and in our queries. This brings me to two guys who have done some excellent work in trying to solve this problem: Fredrik Kalseth and Luke Marshall. I'm going to show you Luke's solution which is detailed in this series of blog posts.
It's based on the specification pattern. If you've not come across this before, Ian Cooper has a great description here. The idea with specifications is that you factor out your domain business logic into small composable classes. You can then test small bits of business logic in isolation and then compose them to create more complex rules; because we all know that rules rely on rules :)
The neat trick is to implement the specification as a lambda expression that can be executed against in-memory object graphs or inserted into an expression tree to be compiled into SQL.
Here's our Total property as a specification, or as Luke calls it, QueryProperty.
static readonly TotalProperty total = new TotalProperty();
[QueryProperty(typeof(TotalProperty))]
public decimal Total
{
get
{
return total.Value(this);
}
}
class TotalProperty : QueryProperty<Order, decimal>
{
public TotalProperty()
: base(order => order.OrderLines.Sum(line => line.Quantity * line.Product.Price))
{
}
}
We factored out the Total calculation into a specification called TotalProperty which passes the rule into the constructor of the QueryProperty base class. We also have a static instance of the TotalProperty specification. This is simply for performance reasons and acts a specification cache. Then in the Total property getter we ask the specification to calculate its value for the current instance.
Note that the Total property is decorated with a QueryPropertyAttribute. This is so that the custom query provider can recognise that this property also supplies a lambda expression via its specification, which is the type specified in the attribute constructor. This is the main weakness of this approach because there's an obvious error waiting to happen. The type passed in the QueryPropertyAttribute has to match the type of the specification. It's also very invasive since we have various bits of the framework (QueryProperty, QueryPropertyAttribute) surfacing in our domain code.
These days simply everyone has a generic repository and Luke is no different. His repository chains a custom query provider before the LINQ-to-SQL query provider that knows how to insert the specification expressions into the expression tree. We can use the repository like this:
[Test]
public void TotalQueryUsingRepository()
{
var repository = new RepositoryDatabase<Order>(dataContext);
var total = repository.AsQueryable().Select(order => order.Total).First();
Assert.That(total, Is.EqualTo(expectedTotal));
}
Note how the LINQ expression is exactly the same as one we ran above which caused five select statements to be executed and the entire Order object graph to be loaded into memory. When we run this new test we get this SQL:
SELECT TOP (1) [t4].[value]
FROM [dbo].[Order] AS [t0]
OUTER APPLY (
SELECT SUM([t3].[value]) AS [value]
FROM (
SELECT (CONVERT(Decimal(29,4),[t1].[Quantity])) * [t2].[Price] AS [value], [t1].[OrderId]
FROM [dbo].[OrderLine] AS [t1]
INNER JOIN [dbo].[Product] AS [t2] ON [t2].[Id] = [t1].[ProductId]
) AS [t3]
WHERE [t3].[OrderId] = [t0].[Id]
) AS [t4]
A single select statement that returns a scalar value for the total. It's very nice, and with the caveats above it's by far the nicest solution to this problem that I've seen yet.